数据库存储
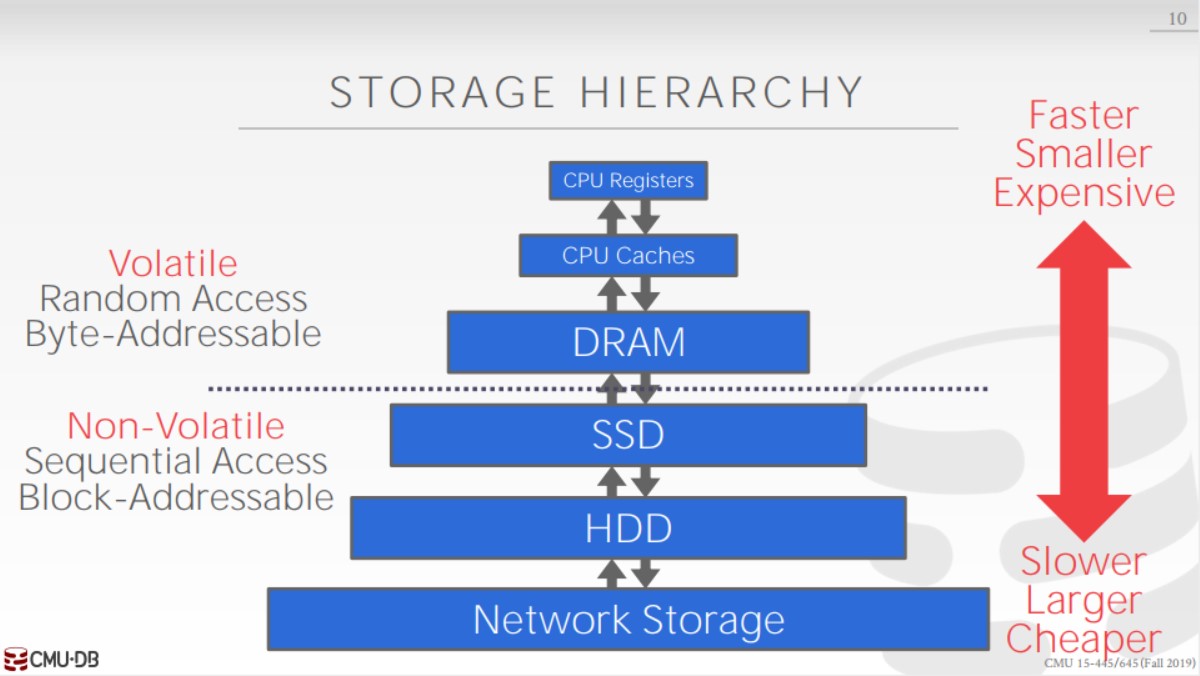
计算机的存储层次如图所示,由上至下速度越来越慢 ,容量越来越大。而CMU 15-445主要在非易失型存储中构建DBMS
面向磁盘的DBMS

磁盘存储着数据文件,并把它们封装成不同的块或者页面来表示它们,buffer pool在内存中,执行引擎向buffer pool进行请求读取某一页的文件,然后buffer pool将其装载进来,然后执行引擎对buffer pool进行操作。
在这个架构与其他软件架构的不同之处就在于内存由DBMS自己来管理而不是交给操作系统来管理。
mmap

mmap指的是从磁盘中获取文件,然后告知操作系统将文件页面映射到进程的地址空间,然后进程可以对这些内存地址进行读写,此时操作系统没有将数据存入内存,但仍能对其写入,具体的方法是借由操作系统,而不是进程自己来写,它通过执行一个Sync来把数据写回磁盘。简单说就是不借助内存,而是进程和操作系统直接通过交换磁盘文件的地址来实现数据的读写。


但由于操作系统只能看到内存在不断的刷新,它不知道数据库在做什么,所以操作系统可能会频繁的读盘(因为它不知道哪些数据是热点,是内存满时哪些数据不应被优先回收的)这也就导致了性能瓶颈。所以为了提升性能我们明显需要更加细粒度的管理内存,这也就是为什么我们需要buffer pool。
操作系统与数据库中的页

最底层的硬件页的大小是4KB,但是像MySQL它的页是16KB,这也就导致了这种情况的发生:如果要写16KB的MySQL页但是硬件页只能保证4KB的写入是原子性的,假如写入8KB以后被意外中断了,恢复后后再写入8KB此时得到的就是两份不连续数据。
Page 目录

数据库维护着一个Page目录文件,这个文件记录着每个页的在磁盘上的位置和该页的剩余空间,并保证Page目录和page是同步的、
Page的结构
page header

Page的组织形式
slotted pages

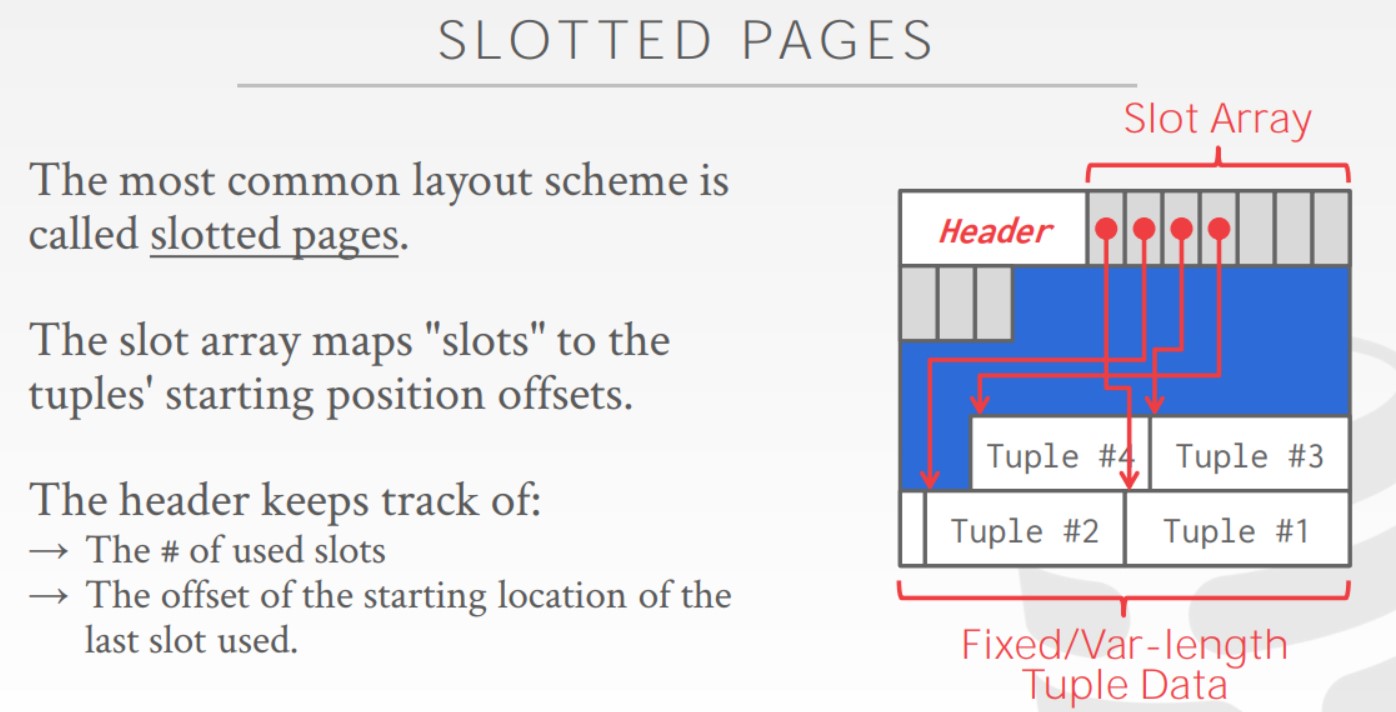
每个page被分成三个部分Header、Slot Array、Tuple。Header用于保存基本额元数据,比如checksum或者访问时间等、Slot Array的作用是将一个特定的slot映射到page上的某个偏移量上,根据这个偏移量来找到所需的tuple。填充Page的方式是从前往后对Slot Array进行填充,数据则是从后向前进行填充。
所以对于上层应用而言,如果想找到一个tuple只需要page id,然后通过每个page里的Slot Array就可以定位到唯一的tuple了。这样的好处在于无论我是移动了整个Page还是移动了Page内的tuple,我们都无需更新索引或者其他一些东西。
log-structed file organization

log-structured file organization 不是将所有的tuple都放在Page中,而是去存储tuple的创建和修改信息。这样做的好处很多比如写入很快,方便回滚等,HDFS和S3就是以这种方式来组织Page。

但是如果要读取那就只能从最新的记录开始上推来找到目标tuple

为了提升读取速度可以给每个tuple建立索引

最终索引目录就是上图所示的形式。一些新出现的数据库HBASE、RocksDB就是用的这种组织形式。
Large Value

假如在有一个很大的tuple,大到一个Page不能将其放下,就会产生overflow page。会有一个overflow page指针来指向那个保存了大tuple的Page。在PostgreSQL中overflow page的阈值是2KB,SQL Server中,如果tuple没法放在一个page内它就会将这个tuple拿出来,并将它放在另一个Page中,MySQL则是当tuple的体积大于该页的一半时产生overflow page。
外部存储

外部存储不会将该属性的数据保存在tuple内部,而是往里面保存一个指针或者文件路径,它们指向能找到该数据的本地文件或网络存储,亦或是某些外部存储设备。
OLTP

OLTP(联机事务处理)的做法是,当从外界拿到新数据时,将它们放到数据库系统中,OLTP只会去读取一小部分数据或者更新一小部分数据,不断地去重复进行相同的操作。
OLAP

OLAP(联机分析处理),当我们已经从OLTP程序中收集到一堆数据后就可以利用OLAP来分析它,并从中推断出新的信息,也可以成为数据科学,即从拥有的数据中试着派生出新的信息,OLAP不会更新数据,它只会试着让已有数据变得更加有意义。
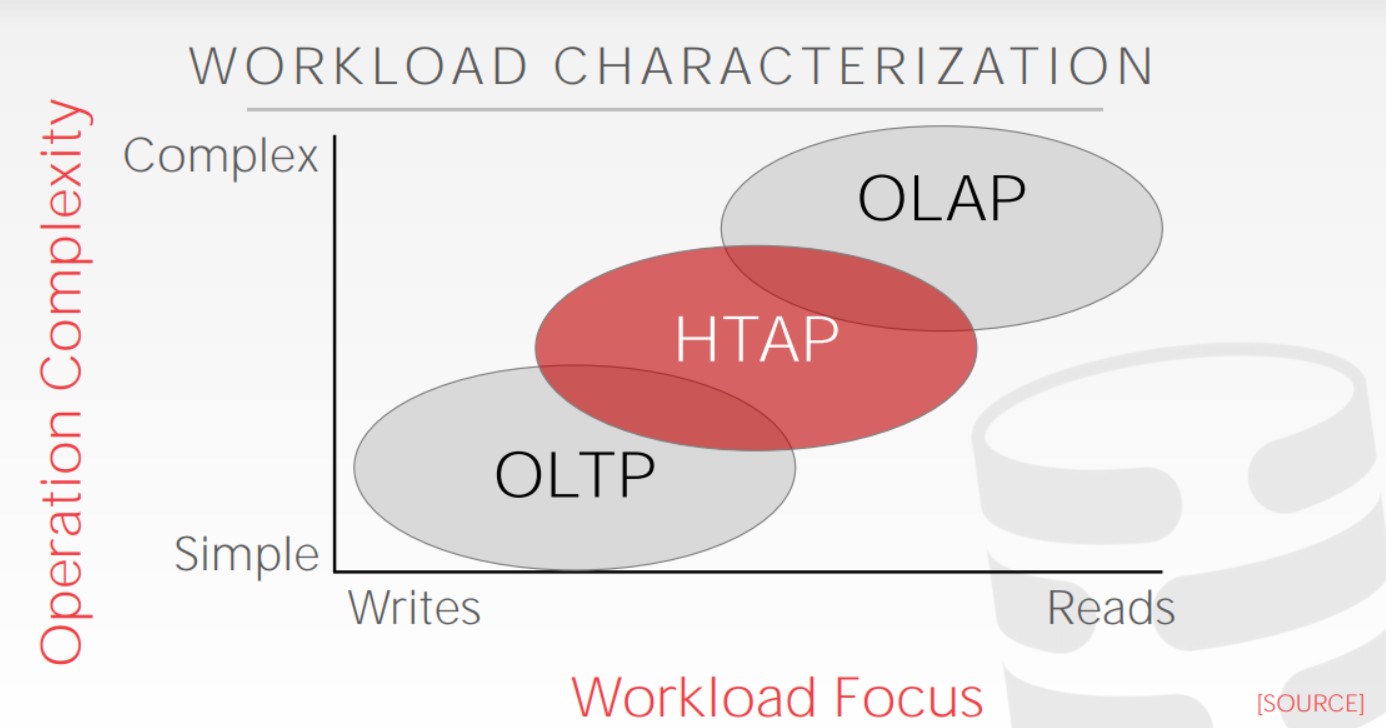
HTAP(混合事务分析处理),融合了OLTP和OLAP的工作。
数据存储模型
行式存储(N-ARY模型)

以行的形式来展示的tuple被称为N-ARY存储模型,它的具体做法是将单个tuple中的所有属性取出,并将它们连续地存储在Page中。例如,如果在已知id的情况下找一条数据,这种模型就非常高效,因为只要找到了page id再找到offset,就可以通过id一次性的读到这条记录的所有的属性。
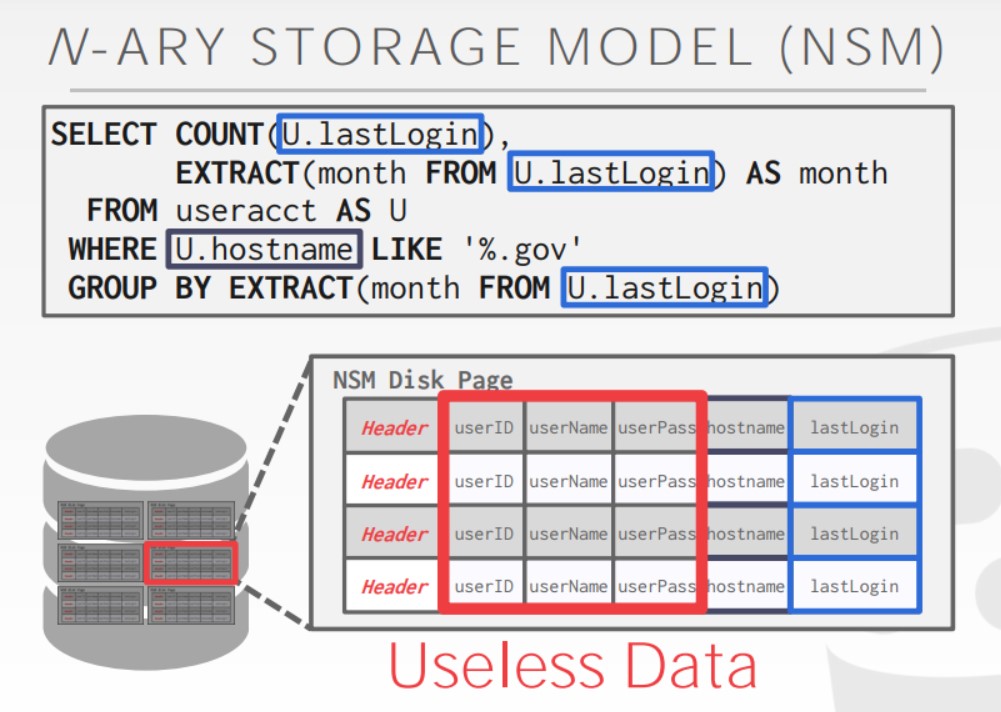
但在做OLAP时,这种存储方式明显不那么高效了,因为我们会不得不读取很多没有必要读取到的数据。

总结一下,在N-ARY存储模型中当访问整个tuple的时候,插入,更新以及删除数据时的速度很快,因为我们本来就是想一次获取单个tuple的全部属性(当然,通常情况下是多个tuple 的全部属性)。但是如果去做一些分析型的查询以及OLAP工作,并且我们想要去扫描整张表大部分的内容时,行式存储明显会变得低效。
列式存储

列式存储的做法不在是将一整个tuple放到一个Page中,而是把横跨多个tuple中单个属性的值保存在单个Page中,也就是将单个列的所有值连续的保存在一起。
tuple标识

既然列式存储,是按属性为单位存储的,那么怎么能区分出那个属性属于哪个tuple呢?解决方案有两种:
- 使用固定长度的偏移量,这意味着对于一列中的每个值来说,它们的长度始终是固定的,当然如果属性是INT类型自然是固定长度的,但是如果是可变类型,就必须压缩所有tuple中的这一属性,让它们统一成一样的长度。
- 对于列中的每一个值,都保存一个主键或是标识符。这种做法的问题就在于每个属性都要浪费额外的空间来存储标识符,所以基本没有哪个数据库采用这种方案。

列式存储的优势在于避免读取不必要的数据节约了IO,劣势在于操作单一数据时会很慢,因为它要结合多个page的内容才能构建出一个完整的tuple。

总结

总结一下,行式存储更适合联机事务处理,列式存储更适合联机分析处理。




